
Do you want to upgrade your skills in Big Data? Well, think no more because the Apache Spark Training is the key to joining the bandwagon of Apache developers. Businesses are quick at generating Big Data, and the need of the hour is rapid data analysis for leveraging relevant business insights. There are several alternatives to processing Big Data – Storm, Hadoop, Spark, and the list goes on. Among them, Spark has revolutionized the Big Data processing ecosystem to become the platform of choice in rapid data analysis.
Hadoop made distributed data analytics possible and had a cluster storage approach. But, Apache Spark offers in-memory distribution and caching of data, facilitating fast writing of Machine Learning algorithms on massive data sets. Apache Spark is growing fast, and there can be no better time to sign-up for the Apache Spark Training.
What is Spark?
Apache Spark is a super-fast and integrated analytics engine for Machine Learning and Big Data. It was originally developed in 2009 at UC Berkeley. With more than 1000 contributors from over 250 organizations, Apache Spark has quickly expanded to become a large-scale open-source community in Big Data processing. Apache Spark has been adopted across a wide range of industries; from Netflix and Yahoo to eBay, major Internet powerhouses have deployed the Apache Spark platform to process massive amounts of data. No doubt, professionals with Spark Training are in high demand.
Apache Spark is an integrated framework that offers rapid processing of large datasets and supports a wide range of Big Data formats, including text data, batch data, graphical data, and more. Here is an overview of the Spark ecosystem’s notable features:
Spark provides enhanced support related to multiple operations of data processing. These include:
- Spark SQL and DataFrames: Spark SQL is a module that allows structured data processing, integrates with the entire ecosystem, acts as a distributed engine for SQL query, and provides DataFrames, a programming abstraction.
- Data Streaming: Spark’s streaming analytics allows analytical and interactive applications across streaming as well as historical data, with fault tolerance and ease of use.
- Machine Learning: MLlib is Spark’s scalable Machine Learning library delivering high-quality algorithms and lightning-fast speed.
- Graphic data processing: GraphX allows interactive building, transformation, and reasoning in graph computation.
Spark has a rich collection of APIs and supports applications written in R, Python, Java, and Scala.
Apache Spark is highly interoperable in terms of its running platform and supported data structure. It can support applications running in the cloud as well as standalone cluster mode. Besides, Spark can access many data structures, including Hadoop data source, HBase, Hive, and more.
Spark is scalable and fault-tolerant with flexibility in streaming, interactive, and batch job processing.
What is RDD?
Spark RDD expedites data processing and enables datasets to be logically partitioned during computation. RDD is the acronym for Resilient Distributed Dataset, where each term denotes its features. Resilient means that RDD is fault-tolerant and enables recomputation in the event of node failure. RDD is distributed, meaning that the Spark RDD datasets reside in multiple nodes, and the dataset signifies the data records that the user will work with.
Spark RDD is used to represent datasets that are distributed across several nodes and which are capable of parallel operation. It is the fundamental data structure of Apache Spark and its principal fault-tolerant abstraction. Spark is an immutable and distributed collection of records that use the cache() and persist() methods to work behind data caching. The records can be created only using coarse-grained operations, meaning that the operations are applied to all of the elements in a dataset. Spark RDD facilitates the logical partitioning of datasets due to its in-memory caching technique. The best part about in-memory caching is that the excess data that doesn’t fit is sent to disk for a recalculation. This feature makes RDD resilient, and you can extract it as and when required, speeding up overall data processing.
The following processes can be used for creating Spark RDD:
- Use of parallelized collections: It involves calling the parallelize method the SparkContext interface on the collection of existing driver programs in Python, Scala or Java. Following is an example in Scala to hold the numbers 7 to 11 as a parallelized collection.
val collection = Array(7, 8, 9, 10, 11)
val prData = spark.sparkContext.parallelize(collection)
- Using external datasets: Apache Spark allows the creation of distributed datasets using Hadoop-supported file storage, including HDFS, HBase, and Local file system.
- Using existing RDDs: Operations such as map, filter, distinct, count, and flatmap are used to transform an existing RDD to a new RDD, without any change to the consistency over the cluster. Example:
Val months =spark.sparkContext.parallelize(Seq(“june”, “july”, “august”, “september”))
val months1= months.map(s => (s.charAt(0), s))
Why is RDD used?
Data sharing and data reuse are common while processing data across multiple jobs in case of computations like Logistic Regression, Page rank algorithms, and K-means clustering. Distributed computing systems like MapReduce allow data sharing and data reuse but suffer from a major problem – the data needs to be stored in a stable, intermediate, distributed store such as Amazon S3 or HDFS. It involves multiple replications, IO operations and serializations, which slow down the overall computation process. RDD solves this problem by employing in-memory computations that are distributed and fault-tolerant.
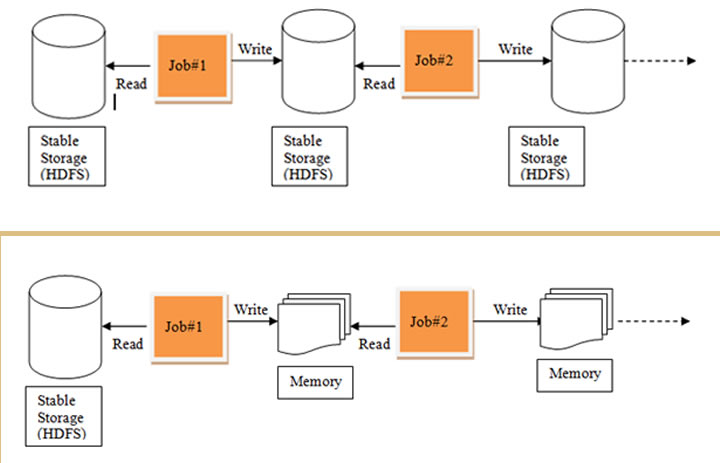
But how does RDD help in fault-tolerance? A set of transformations are used for creating RDDs. So, rather than logging the actual data, RDDs log the transformations. A lineage graph is a graph of transformations that produces one RDD.
firstRDD=spark.textFile(“hdfs://…”)
secondRDD=firstRDD.filter(someFunction);
thirdRDD = secondRDD.map(someFunction);

The major benefit of RDD lies in the fact that if you lose any partition of the RDD, the transformation on that partition can be replayed in lineage to attain the same computation, instead of doing data replication across several nodes. This characteristic of RDD saves a lot of effort in replication and data management to achieve rapid computation.
Conclusion
Apache Spark is extensively used in the Big Data industry. Also, Apache Spark is expected to play a significant role in the next-gen Business Intelligence applications. The demand for Apache Spark developers is growing, and thus, taking the Spark Training can help professionals in getting a holistic, hands-on experience at par with established industry standards.